Inventory of Elements
Each stakeholder agency, company, or group owns, operates, or maintains ITS systems in the region. In this step, a comprehensive inventory of these existing and planned systems is developed based on existing information and stakeholder input.
Definition
ITS Elements are the systems, devices, or equipment, that provide ITS services or share information as part of the ITS services. An inventory also includes non-ITS elements that provide information to or get information from the ITS elements. An comprehensive inventory of "ITS elements" is one of the key building blocks for a regional ITS architecture that represent these systems.
Summary
|
POLICY |
An inventory of existing and planned ITS elements supports development of requirements and information exchanges with these ITS elements as required in 23CFR940.9(d)6 and FTA National ITS Architecture Policy Section 5.d.6.
|
|
APPROACH Key Activities
|
If updating an existing regional ITS architecture: - Review the existing inventory o Use latest planning documents and interview key stakeholders - Revise the inventory o Check RAD-IT inventory for completeness and consistency o Input revisions into RAD-IT - Review inventory updates with stakeholders
If defining a new regional ITS architecture: - Collect existing information o Locate inventory data already be documented in Regional ITS Plans, e.g., EDPs, ITS studies, ITS Project documentation, Requests for Proposals (RFPs), etc. - Create initial inventory o Use collected inventory data to create an initial inventory o Define stakeholder, status, a brief description, and its mapping to ARC-IT physical objects - Review with stakeholders o Review the initial inventory with key stakeholders o Facilitate a broad review and incorporate comments
|
|
INPUT Sources of Information |
- Stakeholders - ITS Plans and Studies (Various) - TIP, STIP, Long Range Transportation Plan, etc.
|
|
OUTPUT
|
- Inventory of existing and planned ITS systems in the region
|
Relationship to Other Components
As shown in the figure below, inventories are mapped to many components of the Regional ITS Architecture. Each element in an inventory includes a name, associated stakeholder(s), a concise description, general status, and the associated physical objects (subsystems or terminators) from ARC-IT. Mapping to ARC-IT allows ITS services, functional requirements, potential interfaces and associated standards, etc. to be identified from the ARC-IT for the element.
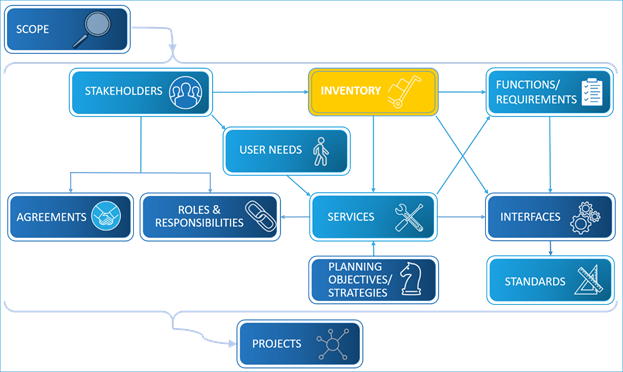
Regional ITS Architecture Components – Inventory
Approach
Whether this is an update to an existing architecture or the development of a completely new architecture the approach for the architecture's inventory involves ensuring the right system elements are identified and mapped to the correct ARC-IT physical objects.
The next sections describe the different activities involved in each approach:
- Developing an Initial Inventory
Updating an Existing Inventory of ITS Elements
For an Architecture Update, the inventory already exists and it is a matter of reviewing, updating, and possibly adding new elements. The basic activities in updating stakeholders are given below.
Review the Existing Inventory
The approach to updating an inventory of ITS elements starts with reviewing the existing inventory information and considering whether the inventory of ITS element in the region has changed since the previous version of the architecture. In addition, existing plans, studies, project documentation, and adjacent or overlapping regional ITS architectures are a good source to use for updating inventory information. A portion of the inventory in adjacent architectures will often be relevant, saving time and improving consistency between adjacent or overlapping architectures.
The ITS Elements inventory covers the geographic, timeframe and services scope specified for the region. Ideally, the previous geographic scope of a region was established so that it represents many existing and planned systems that may be implemented over the timeframe of the architecture, can be developed in a single pass or in multiple passes. For example, an update might start with updating the existing inventory of existing ITS elements, then updating planned elements (i.e., elements that have been programmed), and finally add future elements that may be implemented towards the end of the established timeframe.
Each element in an inventory normally includes a name, associated stakeholder(s), a concise description, general status, and the associated subsystems or terminators from the ARC-IT. A more detailed discussion of these parts of the element definition is given below in the Developing an Inventory of ITS Elements section.
Revise the Inventory
For almost all regional ITS architectures the actual revision of the Inventory of ITS Elements will be done in the RAD-IT Inventory Tab (see discussion on RAD-IT Tab). In addition to including the updates defined in the previous step, the previous version of the Inventory should be checked for completeness and consistency. To begin it is helpful to create a table of Elements sorted by Stakeholder from the previous version. This table will highlight issues such as elements that do not have descriptions, elements that do not have stakeholders assigned, or elements with incorrect status fields.
Use RAD-IT to generate an "Unconnected Elements" table from the Check Your Architecture menu to highlight any elements that are not currently used in any service packages or connected to any other elements.
Another item to consider is whether the Inventory needs to be expanded or compressed. Both the number of stakeholders and the level of detail used in element definition will impact the size of the Inventory. A more detailed description of some of the tradeoffs related to Inventory is contained below in the Developing a New Inventory of ITS Elements section.
Review the list of new stakeholders identified since the last update and interview them to see what ITS elements they have or plan to have in the future.
Review Inventory Updates with Stakeholders
Working closely with the stakeholders as the inventory is updated and refined improves the quality of the inventory and increases stakeholder awareness of the existing and planned transportation systems in the region. Once the inventory has been revised a detailed review with the stakeholders either in workshops, or through web review should be held in order to get consensus on the Inventory update.
 A recommendation is that agencies of similar nature are described in a
consistent manner. For example, the various municipalities might each be named
"City of xxx", while the counties might be named yyy County. This is important
because element information is usually sorted alphabetically, so a consistent
naming convention allows the stakeholders to more easily see their information.
A recommendation is that agencies of similar nature are described in a
consistent manner. For example, the various municipalities might each be named
"City of xxx", while the counties might be named yyy County. This is important
because element information is usually sorted alphabetically, so a consistent
naming convention allows the stakeholders to more easily see their information.
Developing a New Inventory of ITS Elements
A regional ITS architecture inventory is a list of all existing and planned ITS elements in a region as well as non-ITS elements that provide information to or get information from the ITS elements. The focus should be on those elements that support, or may support, interfaces that cross stakeholder boundaries (e.g., inter-agency interfaces, public/private interfaces). Each element in an inventory will normally include a name, associated stakeholder(s), a concise description, general status, and the associated physical objects (subsystems or terminators) from ARC-IT. This core information may be supplemented with specific location information, points of contact, other references, and various implementation details as needs dictate. The region should establish the information that is required for each inventory element based on the needs of the region and available resources.
The fields that are normally included for each inventory element are:
- Element Name: Each element name should be selected with several criteria in mind. Most importantly, the selected name should be easily recognizable by the stakeholders. Preferably, the name will be the "common usage" name for the element in question, or at least be in terms that are familiar to the stakeholders.
- Associated Stakeholders: While stakeholders can participate in the consensus of any part of the regional ITS architecture, they often are most interested in the inventory elements that they own, operate, or maintain. Documenting the association between stakeholders and ITS elements is useful since it allows stakeholders to rapidly identify their own elements. This association helps individual stakeholders make the most effective use of their time. If individual stakeholders don't have time to review the entire regional ITS architecture, they might still be able to review all sections that involve their associated agency, company or interest group, as identified by the associated stakeholder.
- Element Description: While it may be tempting to include very detailed information in the element description when it is available (e.g., the numbers and types of controllers included in a particular ITS element), remember that this level of detail will increase the level of effort required to maintain the regional ITS architecture later. In general, the architecture inventory should not specify technologies or manufacturers since this information is subject to change and incidental to the purpose of the regional ITS architecture. Limit the information to what is required for the stakeholders to recognize the element and its role (i.e., "what does it do?") in the regional ITS architecture. Where a general element is used to represent many systems, the description could include an explicit list of these systems. Additional detailed information that is compiled can be archived separately for later use.
- Physical Object Assignments: Each regional ITS architecture inventory element should be mapped to one or more ARC-IT physical objects, i.e., subsystems and/or terminators. This association must be created because it will lead to identification supporting services, functional objects (and requirements) for the ITS element, and information flows and relevant ITS standards in later steps. Occasionally, an element will be truly unique and not represented in ARC-IT at all. In this case, no ARC-IT association is created. This is a perfectly valid approach, but it does mean that the functionality, information flows, and standards that are identified later for the element will not have a basis in ARC-IT. However, given the wide range of physical objects defined in ARC-IT, most elements can be mapped to an existing physical object.
Collect existing information
The process of creating an inventory of ITS elements starts with collecting existing inventory information. This can often provide an excellent jumpstart to the inventory definition. In addition to existing plans, studies, and project documentation, adjacent or overlapping regional ITS architectures are a good source for inventory information. A portion of the inventory in these architectures will often be relevant, saving time and improving consistency between adjacent or overlapping architectures. It is best to develop a partial inventory based on these resources prior to engaging a large number of stakeholders to make best use of stakeholder time.
 It is helpful to establish a naming convention before assembling
the inventory. For example, the names that are used in the inventory should
start with a standard prefix since the inventory will frequently be viewed and
managed as an alphabetized list of names. Prefixes can be a concise and
consistent reference to the stakeholder (e.g., XYZ Transit), a reference to the
location (City ABC), or any other standard prefix that will group similar ITS
elements when the inventory is sorted alphabetically by name. By establishing
and using a naming convention at the outset, the inventory will be easier to
read and manage, and there will be less rework later to rename and reorganize
the inventory after it is assembled.
It is helpful to establish a naming convention before assembling
the inventory. For example, the names that are used in the inventory should
start with a standard prefix since the inventory will frequently be viewed and
managed as an alphabetized list of names. Prefixes can be a concise and
consistent reference to the stakeholder (e.g., XYZ Transit), a reference to the
location (City ABC), or any other standard prefix that will group similar ITS
elements when the inventory is sorted alphabetically by name. By establishing
and using a naming convention at the outset, the inventory will be easier to
read and manage, and there will be less rework later to rename and reorganize
the inventory after it is assembled.
Create Initial Inventory
When building an inventory, focus first on the "centers" since they are typically involved in the majority of inter-agency and public/private interfaces that need the most attention. Focus next on the field, vehicle, and traveler ITS elements where there is some opportunity for integration. Next consider other ITS elements that are in the region that may interface with ITS. Airports, asset management systems, and special event centers are examples of ITS elements in the region that may provide integration opportunities and should be included in the inventory. Finally, consider centers in adjacent regions, like the TMC in the adjacent state. The objective is to identify the ITS elements in the region that will allow integration opportunities to be identified and considered later in the process. Unless the region has unique needs, don't include ITS elements in the inventory for people (e.g., traffic operations personnel). The focus should be on the systems in the region that may be integrated. Systems with no potential for integration (e.g., an isolated traffic signal in a remote community) need not be included in the inventory.
The inventory should cover the geographic, time horizon and services scope specified for the region. The inventory, representing many existing and planned systems that may be implemented over ten or twenty years, can be developed in a single pass or in multiple passes. For example, you might start with an inventory of existing ITS elements, then add planned elements (i.e., elements that have been programmed), and finally add future elements that may be implemented towards the end of the established timeframe.
The level of granularity in the inventory can vary based on the type of elements and also can vary within a single regional ITS architecture. For example, larger systems in a major metropolitan area may be explicitly identified (e.g., "District 8 Freeway Management Center"), but smaller systems may be represented more broadly with a few general ITS elements (e.g., "Municipal Police Dispatch Centers"). The approach of "rolling up" smaller systems into a general inventory element suggests that these systems should integrate with other regional elements in a consistent fashion. A detailed list of the agencies and systems represented by the general ITS element can be included in the definition for the element. A more detailed discussion of issues associated with granularity of inventory is given below.
An inventory may include a few ITS elements that are outside the defined scope of the region. For example, a Statewide ITS Architecture inventory may include ITS element(s) representing operations centers in adjacent states where there are important interfaces to these operations centers. These shared elements and "inter-regional" interfaces should be coordinated across regions to avoid duplicate and/or conflicting definitions of the same element or interface. The names of the ITS elements in both architectures must be identical when they represent the same system, and the interfaces defined in both regional ITS architectures should be identical when they describe the same information exchange across regional boundaries.
Review with Stakeholders
Working closely with the stakeholders as the inventory is expanded and refined improves the quality of the inventory and increases stakeholder awareness of the existing and planned transportation systems in the region. Many different mechanisms may be used to gather stakeholder input including workshops, smaller meetings, telephone surveys, e-mail, and web-based interactions. Plan to use one or more of these mechanisms to verify and improve the inventory with stakeholder feedback. It may be helpful to engage a few key stakeholders initially and then encourage a broader review once the inventory is substantially complete.
 In general, the inventory should be managed so that it is as small as
possible while still supporting the goal of identifying all key integration
opportunities in the region. For example, instead of identifying separate
inventory elements for each type of field equipment (e.g., separate elements for
variable message signs, signals, cameras, etc.), consider identifying a single
inventory element that includes all of the field equipment.
In general, the inventory should be managed so that it is as small as
possible while still supporting the goal of identifying all key integration
opportunities in the region. For example, instead of identifying separate
inventory elements for each type of field equipment (e.g., separate elements for
variable message signs, signals, cameras, etc.), consider identifying a single
inventory element that includes all of the field equipment.
Multiple ITS elements can be safely grouped into a single inventory element if they exchange the same types of information with the same elements, and if they will be deployed for the same function over time. (E.g. message signs for a freeway and message signs for transit traveler information at a bus stop probably should be identified as separate ITS elements because of the very different requirements for these ITS elements.) The grouping works in the figure below because all the Heartland field equipment interfaces exclusively with the Heartland TOC, and for example, might be part of a single freeway management system deployment project. If some of the field equipment was actually owned and operated by another agency, then it might be best to identify a separate ITS element for that equipment group.
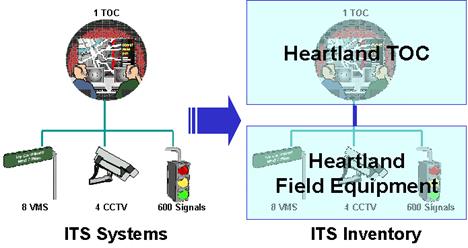
Grouping ITS Elements into General Inventory Items
Another consideration is that when ITS elements are grouped in the inventory, the potential interfaces between these elements are lost (e.g., any potential interface between different types of Heartland field equipment is lost with the grouping in the figure above). Again, the grouping is acceptable because the interface between field equipment is (presumably) not a significant regional interface. The last issue is the affect that that grouping has on ITS standards identification later in the process. Due to the grouping, the combination of ITS standards that support Dynamic Message Signs (DMS), Closed Circuit Television (CCTV) Control, and Signal Control will all be associated with the interface to the combined Field Equipment Element. This means that the ITS standards information for the element must be interpreted and used carefully to ensure that device-specific standards are identified and used properly later in the process. As long as the ITS element grouping is done with these issues in mind, recent experience indicates that grouping will save regional ITS architecture development time with little or no impact to the quality and utility of the final architecture.
RAD-IT
The key information about the ITS elements can be found on the RAD-IT Inventory tab, where the names, descriptions, associated stakeholder, status and mapping to ARC-IT components are contained.
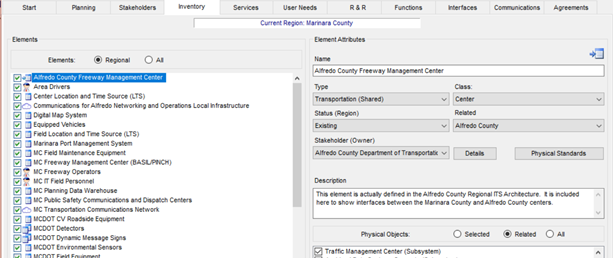
The Inventory tab from RAD-IT is shown above and is the tab where the initial updates of inventories names, associated stakeholders, its descriptions, and associated subsystems/terminators are performed.
Based on the way RAD-IT works, any update to inventory information on the inventory Tab will automatically be available on the Functions and Interfaces tabs, which can then be updated as part of those component updates.
RAD-IT can identify inconsistencies and potential errors in the architectures.
Consider running the "Inventory to Service Package Comparison report" which
compares Inventory and Service Package selections and identifies possible
Inventory and/or Service Package selection gaps. This report identifies ARC-IT
and user defined physical objects and inventory elements that are not assigned
to any Service Package, as well as elements that are not assigned to a Service
Package where it is possible to include them.
Examples
The key ITS Elements inventory is usually described by a table or the Inventory page on the website. In both cases the information is provided alphabetically. Although inventories all tend to include approximately the same information, there are a variety of ways to document this information have. The first example below from the Bay Area Regional ITS Architecture has a web design that does not represent a RAD-IT web generation facility. The second example, from the Ohio Statewide ITS Architecture shows Elements by Stakeholder generated using the RAD-IT web generation facility.

Example of an Inventory Summary from the Bay Area Regional ITS Architecture
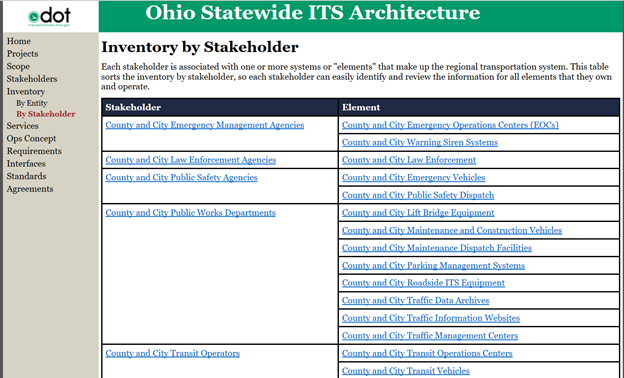
Example of an Inventory Table from the Ohio Statewide ITS Architecture